
作者: 佚名 浏览: 日期:2024-04-29
扫地机器人路径规划是重点目前的还不够智能之前买过一个试用用过几天退了。
个人不了解无人驾驶路径规划,缺乏这个领域的知识。强化学习方面了解一些,希望能给你帮助。
强化学习里面,有一些简单模型,例如让Agent寻找迷宫出路,或许与无人驾驶路径规划类似。
强化学习做这类问题的时候,办法是try-and-error, 也就是大量尝试,根据最终回报(找到出口与否)来更新自己在某个状态(位置)下,选择某个动作(前、后、左、右移动)的价值,从而探索出一个最优策略(optimal policy)。
用强化学习来做这类问题的优势在于,只告诉Agent你的目的(找到出路),而不用告诉它具体怎么做,只要尝试较多次数,Agent总能寻找到较为理想的策略(价值函数收敛),也就是行动路径。
具体算法可以用蒙特卡洛,或者Q-learning, 如果要在Agent探索的同时再利用规划(Planning)的话,可以试用Dyna-Q算法。
具体算法可以查相关文档。
用机器学习(包括增强学习)的方法做路径规划目前还不是一个主流,原因是随着SLAM技术的成熟当周围环境比较简单和确定时(例如稀疏交通流、静态障碍),常规的path planner(图搜索法、内插法、采样法等)已经足够规划出一条比较好的路径。
目前路径规划的难点在于周围交通环境复杂不确定时如何规划出一条安全路径,涉及的主要问题在于如何预测周车交通流的行为。目前学界处理这个问题的主要思路是实时监测周围车辆的意图并用概率模型(如Gaussian Process)预测其未来轨迹,用一个概率化的风险评估函数来对规划路径进行评价,确保规划路径在概率意义下的安全。
增强学习确实可以应对不确定环境,但用增强学习进行路径规划的一个难点在于增强学习本质是基于不断试错的策略改进,你难道想用不断去撞车来优化自己的路径规划算法么?
最近也看了一些强化学习用于路径规划的文章,发现在环境比较稳定的情况,且只有一个智能体存在时,使用传统的非深度学习的方法,如A star, D star,PRM,RPT,人工势场法等,是足够的
但是当智能体数量变多,如多机器人、无人机编队等等场景,需要我们考虑智能体间的协同作用时,传统的方法便不再适用。比较常用的方法是多智能体强化学习 MARL。
关于多机器人路径规划,可以看看我的综述阅读笔记:Trajectory planning for multi-robot systems: Methods and applications 综述阅读笔记
关于MARL,可以看看我整理的博客:多智能体强化学习算法整理
Q-learning是一种强化学习算法,用于解决基于马尔可夫决策过程(MDP)的问题。它通过学习一个值函数来指导智能体在环境中做出决策,以最大化累积奖励。#强化学习 (qq.com)
Q-learning算法的核心思想是使用一个Q值函数来估计每个状态动作对的价值。Q值表示在特定状态下采取某个动作所能获得的预期累积奖励。算法通过不断更新Q值函数来优化智能体的决策策略。#python (qq.com)
Q-learning算法的更新规则如下:
Q(s, a)=Q(s, a) + α * (r + γ * max(Q(s', a')) - Q(s, a))
其中,Q(s, a)表示在状态s下采取动作a的Q值,α是学习率,r是当前状态下采取动作a所获得的即时奖励,γ是折扣因子,s'是下一个状态,a'是在下一个状态下的最优动作。
Q-learning算法的步骤如下:
1. 初始化Q值函数为0或随机值。
2. 在每个时间步骤t,根据当前状态s选择一个动作a。
3. 执行动作a,观察环境返回的奖励r和下一个状态s'。4. 根据Q值函数更新规则更新Q值:Q(s, a)=Q(s, a) + α * (r + γ * max(Q(s', a')) - Q(s, a))。
5. 将下一个状态s'设置为当前状态s。
6. 重复步骤2-5直到达到终止条件。
Q-learning算法的优点是可以在没有环境模型的情况下进行学习,并且可以处理连续状态和动作空间。它在许多领域中都有广泛的应用,如机器人控制、游戏策略和自动驾驶等。#强化学习 (qq.com)
物流配送路径规划问题是指在物流配送过程中,如何合理地安排运输路径,以最小化成本、提高配送效率和满足各种约束条件的问题。该问题在物流领域具有重要的应用价值。
在物流配送路径规划问题中,需要考虑以下因素:
1. 配送需求:包括货物的数量、种类、重量等信息。
2. 配送点:包括供应商、仓库、客户等各个配送点的位置信息。
3. 车辆:包括车辆的数量、容量、速度等信息。
4. 路网:包括道路网络的拓扑结构、距离、通行时间等信息。
5. 约束条件:包括时间窗口约束、车辆容量约束、车辆行驶时间约束等。
为了解决物流配送路径规划问题,研究者们提出了多种优化算法,如遗传算法、粒子群算法、模拟退火算法等。这些算法通过对配送路径进行搜索和优化,以找到最优的配送方案。
在本文中物流配送路径规划问题仅仅考虑路径最短,可以简单抽象为旅行商问题(Traveling salesman problem, TSP)。TSP是一个经典的组合优化问题,它可以描述为一个商品推销员去若干城市推销商品,要求遍历所有城市后回到出发地,目的是选择一个最短的路线。当城市数目较少时,可以使用穷举法求解。而随着城市数增多,求解空间比较复杂,无法使用穷举法求解,因此需要使用优化算法来解决TSP问题。一般地,TSP问题可描述为:一个旅行商需要拜访n个城市,城市之间的距离是已知的,若旅行商对每个城市必须拜访且只拜访一次,求旅行商从某个城市出发并最终回到起点的一条最短路径。#python (qq.com)
可以自动生成地图也可导入自定义地图,只需要修改如下代码中chos的值即可。#python (qq.com)
import matplotlib.pyplot as plt
from Qlearning import Qlearning
#Chos: 1 随机初始化地图; 0 导入固定地图
chos=1
node_num=46#当选择随机初始化地图时,自动随机生成node_num-1个城市
# 创建对象,初始化节点坐标,计算每两点距离
qlearn=Qlearning(alpha=0.5, gamma=0.01, epsilon=0.5, final_epsilon=0.05,chos=chos,node_num=node_num)
# 训练Q表、打印路线
iter_num=8000#训练次数
Curve,BestRoute,Qtable,Map=qlearn.Train_Qtable(iter_num=iter_num)
#Curve 训练曲线
#BestRoute 最优路径
#Qtable Qlearning求解得到的在最优路径下的Q表
#Map TSP的城市节点坐标
## 画图
plt.figure()
plt.ylabel("distance")
plt.xlabel("iter")
plt.plot(Curve, color='green')
plt.title("Q-Learning")
plt.savefig('curve.png')
plt.show()
(1)随机生成15个城市
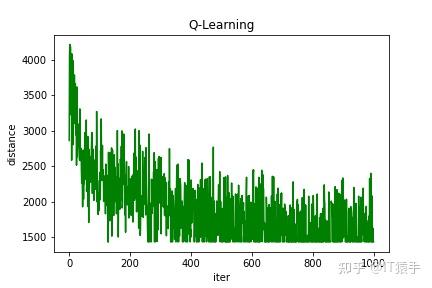
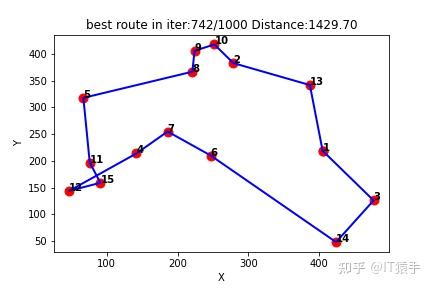
Q-learning得到的最短路线:[1, 3, 14, 6, 7, 4, 12, 15, 11, 5, 8, 9, 10, 2, 13, 1]
(2)随机生成20个城市

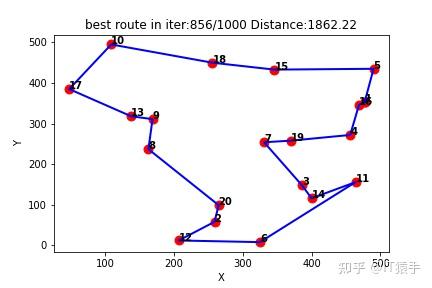
Q-learning得到的最短路线:[1, 16, 4, 19, 7, 3, 14, 11, 6, 12, 2, 20, 8, 9, 13, 17, 10, 18, 15, 5, 1]
(3)随机生成45个城市
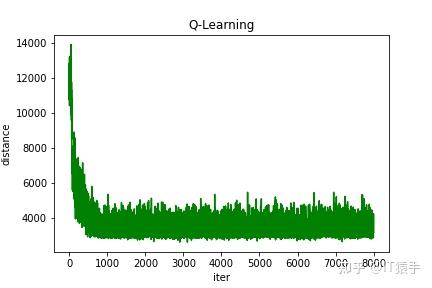
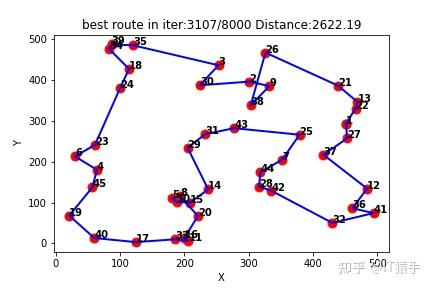
Q-learning得到的最短路线:[1, 27, 37, 12, 36, 41, 32, 42, 28, 44, 7, 25, 43, 31, 29, 14, 15, 10, 5, 8, 20, 16, 11, 33, 17, 40, 19, 45, 4, 6, 23, 24, 18, 34, 39, 35, 3, 30, 2, 9, 38, 26, 21, 13, 22, 1]




