
作者: 佚名 浏览: 日期:2024-07-29
介绍完 HepPlanner 之后,接下来再来看下基于成本优化(CBO)模型在 Calcite 中是如何实现、如何落地的,关于 Volcano 理论内容建议先看下相关理论知识,否则直接看实现的话可能会有一些头大。从 Volcano 模型的理论落地到实践是有很大区别的,这里先看一张 VolcanoPlanner 整体实现图,如下所示(图片来自?Cost-based Query Optimization in Apache Phoenix using Apache Calcite):
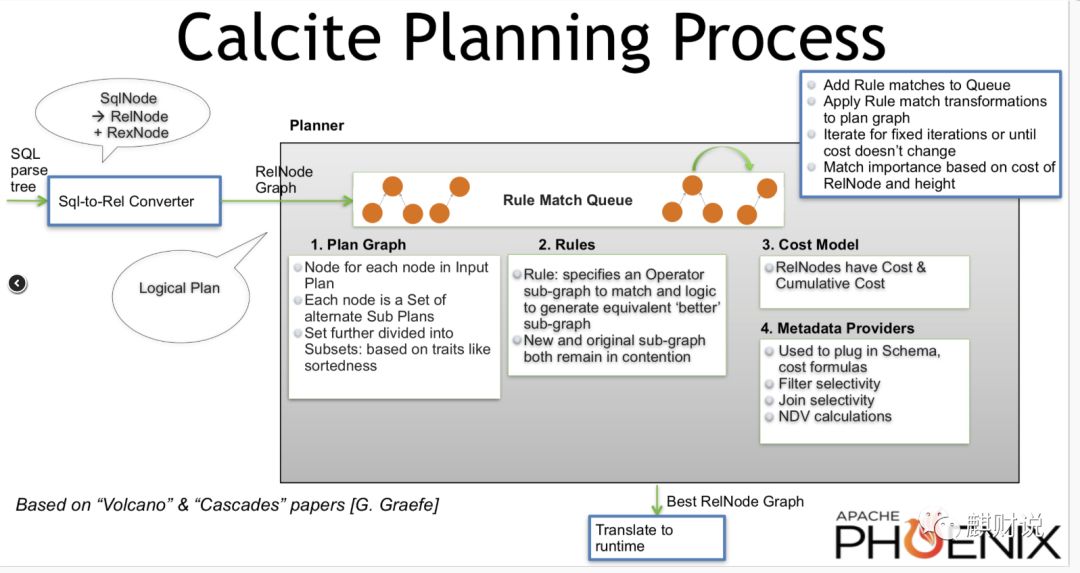
?
上面基本展现了 VolcanoPlanner 内部实现的流程,也简单介绍了 VolcanoPlanner 在实现中的一些关键点(有些概念暂时不了解也不要紧,后面会介绍):
Add Rule matches to Queue:向 Rule Match Queue 中添加相应的 Rule Match;
Apply Rule match transformations to plan gragh:应用 Rule Match 对 plan graph 做 transformation 优化(Rule specifies an Operator sub-graph to match and logic to generate equivalent better sub-graph);
Iterate for fixed iterations or until cost doesn’t change:进行相应的迭代,直到 cost 不再变化或者 Rule Match Queue 中 rule match 已经全部应用完成;
Match importance based on cost of RelNode and height:Rule Match 的 importance 依赖于 RelNode 的 cost 和深度。
使用 VolcanoPlanner 实现的完整代码见?SqlVolcanoTest。
下面来看下 VolcanoPlanner 实现具体的细节。
VolcanoPlanner 在实现中引入了一些基本概念,先明白这些概念对于理解 VolcanoPlanner 的实现非常有帮助。
RelSet
关于 RelSet,源码中介绍如下:
RelSet is an equivalence-set of expressions that is, a set of expressions which have?identical semantics.
We are generally interested in using the expression which has?the lowest cost.
All of the expressions in an RelSet have the?same calling convention.
它有以下特点:
描述一组等价 Relation Expression,所有的 RelNode 会记录在中;
have the same calling convention;
具有相同物理属性的 Relational Expression 会记录在其成员变量中.
RelSet 中比较重要成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | class RelSet {
// 记录属于这个 RelSet 的所有 RelNode
final List<RelNode> rels = new ArrayList<>();
final List<RelNode> parents = new ArrayList<>();
//note: 具体相同物理属性的子集合(本质上 RelSubset 并不记录 RelNode,也是通过 RelSet 按物理属性过滤得到其 RelNode 子集合,见下面的 RelSubset 部分)
final List<RelSubset> subsets = new ArrayList<>();
final List<AbstractConverter> abstractConverters = new ArrayList<>();
RelSet equivalentSet;
RelNode rel;
final Set<CorrelationId> variablesPropagated;
final Set<CorrelationId> variablesUsed;
final int id;
boolean inMetadataQuery;
}
|
关于 RelSubset,源码中介绍如下:
Subset of an equivalence class where all relational expressions have the same physical properties.
它的特点如下:
描述一组物理属性相同的等价 Relation Expression,即它们具有相同的 Physical Properties;
每个 RelSubset 都会记录其所属的 RelSet;
RelSubset 继承自 AbstractRelNode,它也是一种 RelNode,物理属性记录在其成员变量 traitSet 中。
RelSubset 一些比较重要的成员变量如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | public class RelSubset extends AbstractRelNode {
RelOptCost bestCost;
final RelSet set;
RelNode best;
boolean boosted;
//~ Constructors -----------------------------------------------------------
RelSubset(
RelOptCluster cluster,
RelSet set,
RelTraitSet traits) {
super(cluster, traits); // 继承自 AbstractRelNode,会记录其相应的 traits 信息
this.set = set;
this.boosted = false;
assert traits.allSimple();
computeBestCost(cluster.getPlanner()); //note: 计算 best
recomputeDigest(); //note: 计算 digest
}
}
|
每个 RelSubset 都将会记录其最佳 plan()和最佳 plan 的 cost()信息。
RuleMatch
RuleMatch 是这里对 Rule 和 RelSubset 关系的一个抽象,它会记录这两者的信息。
A match of a rule to a particular set of target relational expressions, frozen in time.
importance
importance 决定了在进行 Rule 优化时 Rule 应用的顺序,它是一个相对概念,在 VolcanoPlanner 中有两个 importance,分别是 RelSubset 和 RuleMatch 的 importance,这里先提前介绍一下。
RelSubset 的 importance
RelSubset importance 计算方法见其 api 定义(图中的 sum 改成 Math.max{}这个地方有误):
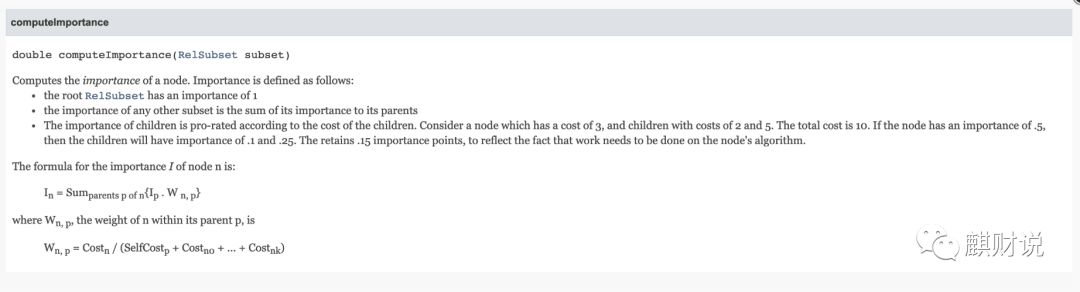
omputeImportance
举个例子:假设一个 RelSubset(记为?s0s0) 的 cost 是3,对应的 importance 是0.5,这个 RelNode 有两个输入(inputs),对应的 RelSubset 记为?s1s1、s2s2(假设?s1s1、s2s2?不再有输入 RelNode),其 cost 分别为 2和5,那么?s1s1?的 importance 为
Importance of?s1s1?=?23+2+523+2+50.5 = 0.1
Importance of?s2s2?=?53+2+553+2+50.5 = 0.25
其中,2代表的是?s1s1?的 cost,3+2+53+2+5?代表的是?s0s0?的 cost(本节点的 cost 加上其所有 input 的 cost)。下面看下其具体的代码实现(调用 RuleQueue 中的计算其 importance):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | //org.apache.calcite.plan.volcano.RuleQueue
public void recompute(RelSubset subset, boolean force) {
Double previousImportance = subsetImportances.get(subset);
if (previousImportance == null) { //note: subset 还没有注册的情况下
if (!force) { //note: 如果不是强制,可以直接先返回
// Subset has not been registered yet. Don't worry about it.
return;
}
previousImportance = Double.NEGATIVE_INFINITY;
}
//note: 计算器 importance 值
double importance = computeImportance(subset);
if (previousImportance == importance) {
return;
}
//note: 缓存中更新其 importance
updateImportance(subset, importance);
}
// 计算一个节点的 importance
double computeImportance(RelSubset subset) {
double importance;
if (subset == planner.root) {
// The root always has importance = 1
//note: root RelSubset 的 importance 为1
importance = 1.0;
} else {
final RelMetadataQuery mq = subset.getCluster().getMetadataQuery();
// The importance of a subset is the max of its importance to its
// parents
//note: 计算其相对于 parent 的最大 importance,多个 parent 的情况下,选择一个最大值
importance = 0.0;
for (RelSubset parent : subset.getParentSubsets(planner)) {
//note: 计算这个 RelSubset 相对于 parent 的 importance
final double childImportance =
computeImportanceOfChild(mq, subset, parent);
//note: 选择最大的 importance
importance = Math.max(importance, childImportance);
}
}
LOGGER.trace("Importance of [{}] is {}", subset, importance);
return importance;
}
//note:根据 cost 计算 child 相对于 parent 的 importance(这是个相对值)
private double computeImportanceOfChild(RelMetadataQuery mq, RelSubset child,
RelSubset parent) {
//note: 获取 parent 的 importance
final double parentImportance = getImportance(parent);
//note: 获取对应的 cost 信息
final double childCost = toDouble(planner.getCost(child, mq));
final double parentCost = toDouble(planner.getCost(parent, mq));
double alpha = childCost / parentCost;
if (alpha >= 1.0) {
// child is always less important than parent
alpha = 0.99;
}
//note: 根据 cost 比列计算其 importance
final double importance = parentImportance * alpha;
LOGGER.trace("Importance of [{}] to its parent [{}] is {} (parent importance={}, child cost={},"
+ " parent cost={})", child, parent, importance, parentImportance, childCost, parentCost);
return importance;
}
|
在中计算 RelSubset 相对于 parent RelSubset 的 importance 时,一个比较重要的地方就是如何计算 cost,关于 cost 的计算见:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | //org.apache.calcite.plan.volcano.VolcanoPlanner
//note: Computes the cost of a RelNode.
public RelOptCost getCost(RelNode rel, RelMetadataQuery mq) {
assert rel != null : "pre-condition: rel != null";
if (rel instanceof RelSubset) { //note: 如果是 RelSubset,证明是已经计算 cost 的 subset
return ((RelSubset) rel).bestCost;
}
if (rel.getTraitSet().getTrait(ConventionTraitDef.INSTANCE)
== Convention.NONE) {
return costFactory.makeInfiniteCost(); //note: 这种情况下也会返回 infinite Cost
}
//note: 计算其 cost
RelOptCost cost = mq.getNonCumulativeCost(rel);
if (!zeroCost.isLt(cost)) { //note: cost 比0还小的情况
// cost must be positive, so nudge it
cost = costFactory.makeTinyCost();
}
//note: RelNode 的 cost 会把其 input 全部加上
for (RelNode input : rel.getInputs()) {
cost = cost.plus(getCost(input, mq));
}
return cost;
}
|
上面就是 RelSubset importance 计算的代码实现,从实现中可以发现这个特点:
越靠近 root 的 RelSubset,其 importance 越大,这个带来的好处就是在优化时,会尽量先优化靠近 root 的 RelNode,这样带来的收益也会最大。
RuleMatch 的 importance
RuleMatch 的 importance 定义为以下两个中比较大的一个(如果对应的 RelSubset 有 importance 的情况下):
这个 RuleMatch 对应 RelSubset(这个 rule match 的 RelSubset)的 importance;
输出的 RelSubset(taget RelSubset)的 importance(如果这个 RelSubset 在 VolcanoPlanner 的缓存中存在的话)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | //org.apache.calcite.plan.volcano.VolcanoRuleMatch
double computeImportance() {
assert rels[0] != null; //note: rels[0] 这个 Rule Match 对应的 RelSubset
RelSubset subset = volcanoPlanner.getSubset(rels[0]);
double importance = 0;
if (subset != null) {
//note: 获取 RelSubset 的 importance
importance = volcanoPlanner.ruleQueue.getImportance(subset);
}
//note: Returns a guess as to which subset the result of this rule will belong to.
final RelSubset targetSubset = guessSubset();
if ((targetSubset != null) && (targetSubset != subset)) {
// If this rule will generate a member of an equivalence class
// which is more important, use that importance.
//note: 获取 targetSubset 的 importance
final double targetImportance =
volcanoPlanner.ruleQueue.getImportance(targetSubset);
if (targetImportance > importance) {
importance = targetImportance;
// If the equivalence class is cheaper than the target, bump up
// the importance of the rule. A converter is an easy way to
// make the plan cheaper, so we'd hate to miss this opportunity.
//
// REVIEW: jhyde, 2007/12/21: This rule seems to make sense, but
// is disabled until it has been proven.
//
// CHECKSTYLE: IGNORE 3
if ((subset != null)
&& subset.bestCost.isLt(targetSubset.bestCost)
&& false) { //note: 肯定不会进入
importance *=
targetSubset.bestCost.divideBy(subset.bestCost);
importance = Math.min(importance, 0.99);
}
}
}
return importance;
}
|
RuleMatch 的 importance 主要是决定了在选择 RuleMatch 时,应该先处理哪一个?它本质上还是直接用的 RelSubset 的 importance。
还是以前面的示例,只不过这里把优化器换成 VolcanoPlanner 来实现,通过这个示例来详细看下 VolcanoPlanner 内部的实现逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | //1. 初始化 VolcanoPlanner 对象,并添加相应的 Rule
VolcanoPlanner planner = new VolcanoPlanner();
planner.addRelTraitDef(ConventionTraitDef.INSTANCE);
planner.addRelTraitDef(RelDistributionTraitDef.INSTANCE);
// 添加相应的 rule
planner.addRule(FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN);
planner.addRule(ReduceExpressionsRule.PROJECT_INSTANCE);
planner.addRule(PruneEmptyRules.PROJECT_INSTANCE);
// 添加相应的 ConverterRule
planner.addRule(EnumerableRules.ENUMERABLE_MERGE_JOIN_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_SORT_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_VALUES_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_PROJECT_RULE);
planner.addRule(EnumerableRules.ENUMERABLE_FILTER_RULE);
//2. Changes a relational expression to an equivalent one with a different set of traits.
RelTraitSet desiredTraits =
relNode.getCluster().traitSet().replace(EnumerableConvention.INSTANCE);
relNode = planner.changeTraits(relNode, desiredTraits);
//3. 通过 VolcanoPlanner 的 setRoot 方法注册相应的 RelNode,并进行相应的初始化操作
planner.setRoot(relNode);
//4. 通过动态规划算法找到 cost 最小的 plan
relNode = planner.findBestExp();
|
优化后的结果为:
1 2 3 4 5 6 7 | EnumerableSort(sort0=[$0], dir0=[ASC])
EnumerableProject(USER_ID=[$0], USER_NAME=[$1], USER_COMPANY=[$5], USER_AGE=[$2])
EnumerableMergeJoin(condition=[=($0, $3)], joinType=[inner])
EnumerableFilter(condition=[>($2, 30)])
EnumerableTableScan(table=[[USERS]])
EnumerableFilter(condition=[>($0, 10)])
EnumerableTableScan(table=[[JOBS]])
|
在应用 VolcanoPlanner 时,整体分为以下四步:
初始化 VolcanoPlanner,并添加相应的 Rule(包括 ConverterRule);
对 RelNode 做等价转换,这里只是改变其物理属性();
通过 VolcanoPlanner 的方法注册相应的 RelNode,并进行相应的初始化操作;
通过动态规划算法找到 cost 最小的 plan;
下面来分享一下上面的详细流程。
1. VolcanoPlanner 初始化
在这里总共有三步,分别是 VolcanoPlanner 初始化,?添加 RelTraitDef,添加 rule,先看下 VolcanoPlanner 的初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | //org.apache.calcite.plan.volcano.VolcanoPlanner
public VolcanoPlanner() {
this(null, null);
}
public VolcanoPlanner(RelOptCostFactory costFactory, //
Context externalContext) {
super(costFactory == null ? VolcanoCost.FACTORY : costFactory, //
externalContext);
this.zeroCost = this.costFactory.makeZeroCost();
}
|
这里其实并没有做什么,只是做了一些简单的初始化,如果要想设置相应 RelTraitDef 的话,需要调用进行添加,其实现如下:
1 2 3 4 5 | //org.apache.calcite.plan.volcano.VolcanoPlanner
//note: 添加 RelTraitDef
@Override public boolean addRelTraitDef(RelTraitDef relTraitDef) {
return !traitDefs.contains(relTraitDef) && traitDefs.add(relTraitDef);
}
|
如果要给 VolcanoPlanner 添加 Rule 的话,需要调用进行添加,在这个方法里重点做的一步是将具体的 RelNode 与 RelOptRuleOperand 之间的关系记录下来,记录到中,相当于在优化时,哪个 RelNode 可以应用哪些 Rule 都是记录在这个缓存里的。其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | //org.apache.calcite.plan.volcano.VolcanoPlanner
//note: 添加 rule
public boolean addRule(RelOptRule rule) {
if (locked) {
return false;
}
if (ruleSet.contains(rule)) {
// Rule already exists.
return false;
}
final boolean added = ruleSet.add(rule);
assert added;
final String ruleName = rule.toString();
//note: 这里的 ruleNames 允许重复的 key 值,但是这里还是要求 rule description 保持唯一的,与 rule 一一对应
if (ruleNames.put(ruleName, rule.getClass())) {
Set<Class> x = ruleNames.get(ruleName);
if (x.size() > 1) {
throw new RuntimeException("Rule description '" + ruleName
+ "' is not unique; classes: " + x);
}
}
//note: 注册一个 rule 的 description(保存在 mapDescToRule 中)
mapRuleDescription(rule);
// Each of this rule's operands is an 'entry point' for a rule call. Register each operand against all concrete sub-classes that could match it.
//note: 记录每个 sub-classes 与 operand 的关系(如果能 match 的话,就记录一次)。一个 RelOptRuleOperand 只会有一个 class 与之对应,这里找的是 subclass
for (RelOptRuleOperand operand : rule.getOperands()) {
for (Class<? extends RelNode> subClass
: subClasses(operand.getMatchedClass())) {
classOperands.put(subClass, operand);
}
}
// If this is a converter rule, check that it operates on one of the
// kinds of trait we are interested in, and if so, register the rule
// with the trait.
//note: 对于 ConverterRule 的操作,如果其 ruleTraitDef 类型包含在我们初始化的 traitDefs 中,
//note: 就注册这个 converterRule 到 ruleTraitDef 中
//note: 如果不包含 ruleTraitDef,这个 ConverterRule 在本次优化的过程中是用不到的
if (rule instanceof ConverterRule) {
ConverterRule converterRule = (ConverterRule) rule;
final RelTrait ruleTrait = converterRule.getInTrait();
final RelTraitDef ruleTraitDef = ruleTrait.getTraitDef();
if (traitDefs.contains(ruleTraitDef)) { //note: 这里注册好像也没有用到
ruleTraitDef.registerConverterRule(this, converterRule);
}
}
return true;
}
|
2. RelNode changeTraits
这里分为两步:
通过 RelTraitSet 的方法,将 RelTraitSet 中对应的 RelTraitDef 做对应的更新,其他的 RelTrait 不变;
这一步简单来说就是:Changes a relational expression to an equivalent one with a different set of traits,对相应的 RelNode 做 converter 操作,这里实际上也会做很多的内容,这部分会放在第三步讲解,主要是方法的实现。
3. VolcanoPlanner setRoot
VolcanoPlanner 会调用方法注册相应的 Root RelNode,并进行一系列 Volcano 必须的初始化操作,很多的操作都是在这里实现的,这里来详细看下其实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | //org.apache.calcite.plan.volcano.VolcanoPlanner
public void setRoot(RelNode rel) {
// We're registered all the rules, and therefore RelNode classes,
// we're interested in, and have not yet started calling metadata providers.
// So now is a good time to tell the metadata layer what to expect.
registerMetadataRels();
//note: 注册相应的 RelNode,会做一系列的初始化操作, RelNode 会有对应的 RelSubset
this.root = registerImpl(rel, null);
if (this.originalRoot == null) {
this.originalRoot = rel;
}
// Making a node the root changes its importance.
//note: 重新计算 root subset 的 importance
this.ruleQueue.recompute(this.root);
//Ensures that the subset that is the root relational expression contains converters to all other subsets in its equivalence set.
ensureRootConverters();
}
|
对于方法来说,核心的处理流程是在方法中,在这个方法会进行相应的初始化操作(包括 RelNode 到 RelSubset 的转换、计算 RelSubset 的 importance 等),其他的方法在上面有相应的备注,这里我们看下具体做了哪些事情:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 | //org.apache.calcite.plan.volcano.VolcanoPlanner
private RelSubset registerImpl(
RelNode rel,
RelSet set) {
if (rel instanceof RelSubset) { //note: 如果是 RelSubset 类型,已经注册过了
return registerSubset(set, (RelSubset) rel); //note: 做相应的 merge
}
assert !isRegistered(rel) : "already been registered: " + rel;
if (rel.getCluster().getPlanner() != this) { //note: cluster 中 planner 与这里不同
throw new AssertionError("Relational expression " + rel
+ " belongs to a different planner than is currently being used.");
}
// Now is a good time to ensure that the relational expression
// implements the interface required by its calling convention.
//note: 确保 relational expression 可以实施其 calling convention 所需的接口
//note: 获取 RelNode 的 RelTraitSet
final RelTraitSet traits = rel.getTraitSet();
//note: 获取其 ConventionTraitDef
final Convention convention = traits.getTrait(ConventionTraitDef.INSTANCE);
assert convention != null;
if (!convention.getInterface().isInstance(rel)
&& !(rel instanceof Converter)) {
throw new AssertionError("Relational expression " + rel
+ " has calling-convention " + convention
+ " but does not implement the required interface '"
+ convention.getInterface() + "' of that convention");
}
if (traits.size() != traitDefs.size()) {
throw new AssertionError("Relational expression " + rel
+ " does not have the correct number of traits: " + traits.size()
+ " != " + traitDefs.size());
}
// Ensure that its sub-expressions are registered.
//note: 其实现在 AbstractRelNode 对应的方法中,实际上调用的还是 ensureRegistered 方法进行注册
//note: 将 RelNode 的所有 inputs 注册到 planner 中
//note: 这里会递归调用 registerImpl 注册 relNode 与 RelSet,直到其 inputs 全部注册
//note: 返回的是一个 RelSubset 类型
rel = rel.onRegister(this);
// Record its provenance. (Rule call may be null.)
//note: 记录 RelNode 的来源
if (ruleCallStack.isEmpty()) { //note: 不知道来源时
provenanceMap.put(rel, Provenance.EMPTY);
} else { //note: 来自 rule 触发的情况
final VolcanoRuleCall ruleCall = ruleCallStack.peek();
provenanceMap.put(
rel,
new RuleProvenance(
ruleCall.rule,
ImmutableList.copyOf(ruleCall.rels),
ruleCall.id));
}
// If it is equivalent to an existing expression, return the set that
// the equivalent expression belongs to.
//note: 根据 RelNode 的 digest(摘要,全局唯一)判断其是否已经有对应的 RelSubset,有的话直接放回
String key = rel.getDigest();
RelNode equivExp = mapDigestToRel.get(key);
if (equivExp == null) { //note: 还没注册的情况
// do nothing
} else if (equivExp == rel) {//note: 已经有其缓存信息
return getSubset(rel);
} else {
assert RelOptUtil.equal(
"left", equivExp.getRowType(),
"right", rel.getRowType(),
Litmus.THROW);
RelSet equivSet = getSet(equivExp); //note: 有 RelSubset 但对应的 RelNode 不同时,这里对其 RelSet 做下 merge
if (equivSet != null) {
LOGGER.trace(
"Register: rel#{} is equivalent to {}", rel.getId(), equivExp.getDescription());
return registerSubset(set, getSubset(equivExp));
}
}
//note: Converters are in the same set as their children.
if (rel instanceof Converter) {
final RelNode input = ((Converter) rel).getInput();
final RelSet childSet = getSet(input);
if ((set != null)
&& (set != childSet)
&& (set.equivalentSet == null)) {
LOGGER.trace(
"Register #{} {} (and merge sets, because it is a conversion)",
rel.getId(), rel.getDigest());
merge(set, childSet);
registerCount++;
// During the mergers, the child set may have changed, and since
// we're not registered yet, we won't have been informed. So
// check whether we are now equivalent to an existing
// expression.
if (fixUpInputs(rel)) {
rel.recomputeDigest();
key = rel.getDigest();
RelNode equivRel = mapDigestToRel.get(key);
if ((equivRel != rel) && (equivRel != null)) {
assert RelOptUtil.equal(
"rel rowtype",
rel.getRowType(),
"equivRel rowtype",
equivRel.getRowType(),
Litmus.THROW);
// make sure this bad rel didn't get into the
// set in any way (fixupInputs will do this but it
// doesn't know if it should so it does it anyway)
set.obliterateRelNode(rel);
// There is already an equivalent expression. Use that
// one, and forget about this one.
return getSubset(equivRel);
}
}
} else {
set = childSet;
}
}
// Place the expression in the appropriate equivalence set.
//note: 把 expression 放到合适的 等价集 中
//note: 如果 RelSet 不存在,这里会初始化一个 RelSet
if (set == null) {
set = new RelSet(
nextSetId++,
Util.minus(
RelOptUtil.getVariablesSet(rel),
rel.getVariablesSet()),
RelOptUtil.getVariablesUsed(rel));
this.allSets.add(set);
}
// Chain to find 'live' equivalent set, just in case several sets are
// merging at the same time.
//note: 递归查询,一直找到最开始的 语义相等的集合,防止不同集合同时被 merge
while (set.equivalentSet != null) {
set = set.equivalentSet;
}
// Allow each rel to register its own rules.
registerClass(rel);
registerCount++;
//note: 初始时是 0
final int subsetBeforeCount = set.subsets.size();
//note: 向等价集中添加相应的 RelNode,并更新其 best 信息
RelSubset subset = addRelToSet(rel, set);
//note: 缓存相关信息,返回的 key 之前对应的 value
final RelNode xx = mapDigestToRel.put(key, rel);
assert xx == null || xx == rel : rel.getDigest();
LOGGER.trace("Register {} in {}", rel.getDescription(), subset.getDescription());
// This relational expression may have been registered while we
// recursively registered its children. If this is the case, we're done.
if (xx != null) {
return subset;
}
// Create back-links from its children, which makes children more
// important.
//note: 如果是 root,初始化其 importance 为 1.0
if (rel == this.root) {
ruleQueue.subsetImportances.put(
subset,
1.0); // todo: remove
}
//note: 将 Rel 的 input 对应的 RelSubset 的 parents 设置为当前的 Rel
//note: 也就是说,一个 RelNode 的 input 为其对应 RelSubset 的 children 节点
for (RelNode input : rel.getInputs()) {
RelSubset childSubset = (RelSubset) input;
childSubset.set.parents.add(rel);
// Child subset is more important now a new parent uses it.
//note: 重新计算 RelSubset 的 importance
ruleQueue.recompute(childSubset);
}
if (rel == this.root) {// TODO: 2019-03-11 这里为什么要删除呢?
ruleQueue.subsetImportances.remove(subset);
}
// Remember abstract converters until they're satisfied
//note: 如果是 AbstractConverter 示例,添加到 abstractConverters 集合中
if (rel instanceof AbstractConverter) {
set.abstractConverters.add((AbstractConverter) rel);
}
// If this set has any unsatisfied converters, try to satisfy them.
//note: check set.abstractConverters
checkForSatisfiedConverters(set, rel);
// Make sure this rel's subset importance is updated
//note: 强制更新(重新计算) subset 的 importance
ruleQueue.recompute(subset, true);
//note: 触发所有匹配的 rule,这里是添加到对应的 RuleQueue 中
// Queue up all rules triggered by this relexp's creation.
fireRules(rel, true);
// It's a new subset.
//note: 如果是一个 new subset,再做一次触发
if (set.subsets.size() > subsetBeforeCount) {
fireRules(subset, true);
}
return subset;
}
|
?处理流程比较复杂,其方法实现,可以简单总结为以下几步:
在经过最上面的一些验证之后,会通过这步操作,递归地调用 VolcanoPlanner 的方法对其RelNode 进行注册,最后还是调用方法先注册叶子节点,然后再父节点,最后到根节点;
根据 RelNode 的 digest 信息(一般这个对于 RelNode 来说是全局唯一的),判断其是否已经存在缓存中,如果存在的话,那么判断会 RelNode 是否相同,如果相同的话,证明之前已经注册过,直接通过返回其对应的 RelSubset 信息,否则就对其 RelSubset 做下 merge;
如果 RelNode 对应的 RelSet 为 null,这里会新建一个 RelSet,并通过将 RelNode 添加到 RelSet 中,并且更新 VolcanoPlanner 的缓存记录(RelNode 与 RelSubset 的对应关系),在的最后还会更新 RelSubset 的 best plan 和 best cost(每当往一个 RelSubset 添加相应的 RelNode 时,都会判断这个 RelNode 是否代表了 best plan,如果是的话,就更新);
将这个 RelNode 的 inputs 设置为其对应 RelSubset 的 children 节点(实际的操作时,是在 RelSet 的中记录其父节点);
强制重新计算当前 RelNode 对应 RelSubset 的 importance;
如果这个 RelSubset 是新建的,会再触发一次方法(会先对 RelNode 触发一次),遍历找到所有可以 match 的 Rule,对每个 Rule 都会创建一个 VolcanoRuleMatch 对象(会记录 RelNode、RelOptRuleOperand 等信息,RelOptRuleOperand 中又会记录 Rule 的信息),并将这个 VolcanoRuleMatch 添加到对应的 RuleQueue 中(就是前面图中的那个 RuleQueue)。
这里,来看下方法的实现,它的目的是把配置的 RuleMatch 添加到 RuleQueue 中,其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | //org.apache.calcite.plan.volcano.VolcanoPlanner
void fireRules(
RelNode rel,
boolean deferred) {
for (RelOptRuleOperand operand : classOperands.get(rel.getClass())) {
if (operand.matches(rel)) { //note: rule 匹配的情况
final VolcanoRuleCall ruleCall;
if (deferred) { //note: 这里默认都是 true,会把 RuleMatch 添加到 queue 中
ruleCall = new DeferringRuleCall(this, operand);
} else {
ruleCall = new VolcanoRuleCall(this, operand);
}
ruleCall.match(rel);
}
}
}
private static class DeferringRuleCall extends VolcanoRuleCall {
DeferringRuleCall(
VolcanoPlanner planner,
RelOptRuleOperand operand) {
super(planner, operand);
}
protected void onMatch() {
final VolcanoRuleMatch match =
new VolcanoRuleMatch(
volcanoPlanner,
getOperand0(), //note: 其实就是 operand
rels,
nodeInputs);
volcanoPlanner.ruleQueue.addMatch(match);
}
}
|
在上面的方法中,对于匹配的 Rule,将会创建一个 VolcanoRuleMatch 对象,之后再把这个 VolcanoRuleMatch 对象添加到对应的 RuleQueue 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | //org.apache.calcite.plan.volcano.RuleQueue
void addMatch(VolcanoRuleMatch match) {
final String matchName = match.toString();
for (PhaseMatchList matchList : matchListMap.values()) {
if (!matchList.names.add(matchName)) {
// Identical match has already been added.
continue;
}
String ruleClassName = match.getRule().getClass().getSimpleName();
Set<String> phaseRuleSet = phaseRuleMapping.get(matchList.phase);
//note: 如果 phaseRuleSet 不为 ALL_RULES,并且 phaseRuleSet 不包含这个 ruleClassName 时,就跳过(其他三个阶段都属于这个情况)
//note: 在添加 rule match 时,phaseRuleSet 可以控制哪些 match 可以添加、哪些不能添加
//note: 这里的话,默认只有处在 OPTIMIZE 阶段的 PhaseMatchList 可以添加相应的 rule match
if (phaseRuleSet != ALL_RULES) {
if (!phaseRuleSet.contains(ruleClassName)) {
continue;
}
}
LOGGER.trace("{} Rule-match queued: {}", matchList.phase.toString(), matchName);
matchList.list.add(match);
matchList.matchMap.put(
planner.getSubset(match.rels[0]), match);
}
}
|
到这里 VolcanoPlanner 需要初始化的内容都初始化完成了,下面就到了具体的优化部分。
4. VolcanoPlanner findBestExp
VolcanoPlanner 的是具体进行优化的地方,先介绍一下这里的优化策略(每进行一次迭代,?加1,它记录了总的迭代次数):
第一次找到可执行计划的迭代次数记为?,其对应的 Cost 暂时记为 BestCost;
制定下一次优化要达到的目标为?,再根据及当前的迭代次数计算?,这个值代表的意思是:如果迭代次数超过这个值还没有达到优化目标,那么将会放弃迭代,认为当前的 plan 就是 best plan;
如果 RuleQueue 中 RuleMatch 为空,那么也会退出迭代,认为当前的 plan 就是 best plan;
在每次迭代时都会从 RuleQueue 中选择一个 RuleMatch,策略是选择一个最高 importance 的 RuleMatch,可以保证在每次规则优化时都是选择当前优化效果最好的 Rule 去优化;
最后根据 best plan,构建其对应的 RelNode。
上面就是主要设计理念,这里来看其具体的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 | //org.apache.calcite.plan.volcano.VolcanoPlanner
public RelNode findBestExp() {
//note: 确保 root relational expression 的 subset(RelSubset)在它的等价集(RelSet)中包含所有 RelSubset 的 converter
//note: 来保证 planner 从其他的 subsets 找到的实现方案可以转换为 root,否则可能因为 convention 不同,无法实施
ensureRootConverters();
//note: materialized views 相关,这里可以先忽略~
registerMaterializations();
int cumulativeTicks = 0; //note: 四个阶段通用的变量
//note: 不同的阶段,总共四个阶段,实际上只有 OPTIMIZE 这个阶段有效,因为其他阶段不会有 RuleMatch
for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) {
//note: 在不同的阶段,初始化 RelSubSets 相应的 importance
//note: root 节点往下子节点的 importance 都会被初始化
setInitialImportance();
//note: 默认是 VolcanoCost
RelOptCost targetCost = costFactory.makeHugeCost();
int tick = 0;
int firstFiniteTick = -1;
int splitCount = 0;
int giveUpTick = Integer.MAX_VALUE;
while (true) {
++tick;
++cumulativeTicks;
//note: 第一次运行是 false,两个不是一个对象,一个是 costFactory.makeHugeCost, 一个是 costFactory.makeInfiniteCost
//note: 如果低于目标 cost,这里再重新设置一个新目标、新的 giveUpTick
if (root.bestCost.isLe(targetCost)) {
//note: 本阶段第一次运行,目的是为了调用 clearImportanceBoost 方法,清除相应的 importance 信息
if (firstFiniteTick < 0) {
firstFiniteTick = cumulativeTicks;
//note: 对于那些手动提高 importance 的 RelSubset 进行重新计算
clearImportanceBoost();
}
if (ambitious) {
// Choose a slightly more ambitious target cost, and
// try again. If it took us 1000 iterations to find our
// first finite plan, give ourselves another 100
// iterations to reduce the cost by 10%.
//note: 设置 target 为当前 best cost 的 0.9,调整相应的目标,再进行优化
targetCost = root.bestCost.multiplyBy(0.9);
++splitCount;
if (impatient) {
if (firstFiniteTick < 10) {
// It's possible pre-processing can create
// an implementable plan -- give us some time
// to actually optimize it.
//note: 有可能在 pre-processing 阶段就实现一个 implementable plan,所以先设置一个值,后面再去优化
giveUpTick = cumulativeTicks + 25;
} else {
giveUpTick =
cumulativeTicks
+ Math.max(firstFiniteTick / 10, 25);
}
}
} else {
break;
}
//note: 最近没有任何进步(超过 giveUpTick 限制,还没达到目标值),直接采用当前的 best plan
} else if (cumulativeTicks > giveUpTick) {
// We haven't made progress recently. Take the current best.
break;
} else if (root.bestCost.isInfinite() && ((tick % 10) == 0)) {
injectImportanceBoost();
}
LOGGER.debug("PLANNER = {}; TICK = {}/{}; PHASE = {}; COST = {}",
this, cumulativeTicks, tick, phase.toString(), root.bestCost);
VolcanoRuleMatch match = ruleQueue.popMatch(phase);
//note: 如果没有规则,会直接退出当前的阶段
if (match == null) {
break;
}
assert match.getRule().matches(match);
//note: 做相应的规则匹配
match.onMatch();
// The root may have been merged with another
// subset. Find the new root subset.
root = canonize(root);
}
//note: 当期阶段完成,移除 ruleQueue 中记录的 rule-match list
ruleQueue.phaseCompleted(phase);
}
if (LOGGER.isTraceEnabled()) {
StringWriter sw = new StringWriter();
final PrintWriter pw = new PrintWriter(sw);
dump(pw);
pw.flush();
LOGGER.trace(sw.toString());
}
//note: 根据 plan 构建其 RelNode 树
RelNode cheapest = root.buildCheapestPlan(this);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug(
"Cheapest plan:
{}", RelOptUtil.toString(cheapest, SqlExplainLevel.ALL_ATTRIBUTES));
LOGGER.debug("Provenance:
{}", provenance(cheapest));
}
return cheapest;
}
|
整体的流程正如前面所述,这里来看下 RuleQueue 中方法的实现,它的目的是选择 the highest importance 的 RuleMatch,这个方法的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 | //org.apache.calcite.plan.volcano.RuleQueue
VolcanoRuleMatch popMatch(VolcanoPlannerPhase phase) {
dump();
//note: 选择当前阶段对应的 PhaseMatchList
PhaseMatchList phaseMatchList = matchListMap.get(phase);
if (phaseMatchList == null) {
throw new AssertionError("Used match list for phase " + phase
+ " after phase complete");
}
final List<VolcanoRuleMatch> matchList = phaseMatchList.list;
VolcanoRuleMatch match;
for (;;) {
//note: 按照前面的逻辑只有在 OPTIMIZE 阶段,PhaseMatchList 才不为空,其他阶段都是空
// 参考 addMatch 方法
if (matchList.isEmpty()) {
return null;
}
if (LOGGER.isTraceEnabled()) {
matchList.sort(MATCH_COMPARATOR);
match = matchList.remove(0);
StringBuilder b = new StringBuilder();
b.append("Sorted rule queue:");
for (VolcanoRuleMatch match2 : matchList) {
final double importance = match2.computeImportance();
b.append("
");
b.append(match2);
b.append(" importance ");
b.append(importance);
}
LOGGER.trace(b.toString());
} else { //note: 直接遍历找到 importance 最大的 match(上面先做排序,是为了输出日志)
// If we're not tracing, it's not worth the effort of sorting the
// list to find the minimum.
match = null;
int bestPos = -1;
int i = -1;
for (VolcanoRuleMatch match2 : matchList) {
++i;
if (match == null
|| MATCH_COMPARATOR.compare(match2, match) < 0) {
bestPos = i;
match = match2;
}
}
match = matchList.remove(bestPos);
}
if (skipMatch(match)) {
LOGGER.debug("Skip match: {}", match);
} else {
break;
}
}
// A rule match's digest is composed of the operand RelNodes' digests,
// which may have changed if sets have merged since the rule match was
// enqueued.
//note: 重新计算一下这个 RuleMatch 的 digest
match.recomputeDigest();
//note: 从 phaseMatchList 移除这个 RuleMatch
phaseMatchList.matchMap.remove(
planner.getSubset(match.rels[0]), match);
LOGGER.debug("Pop match: {}", match);
return match;
}
|
到这里,我们就把 VolcanoPlanner 的优化讲述完了,当然并没有面面俱到所有的细节,VolcanoPlanner 的整体处理图如下:
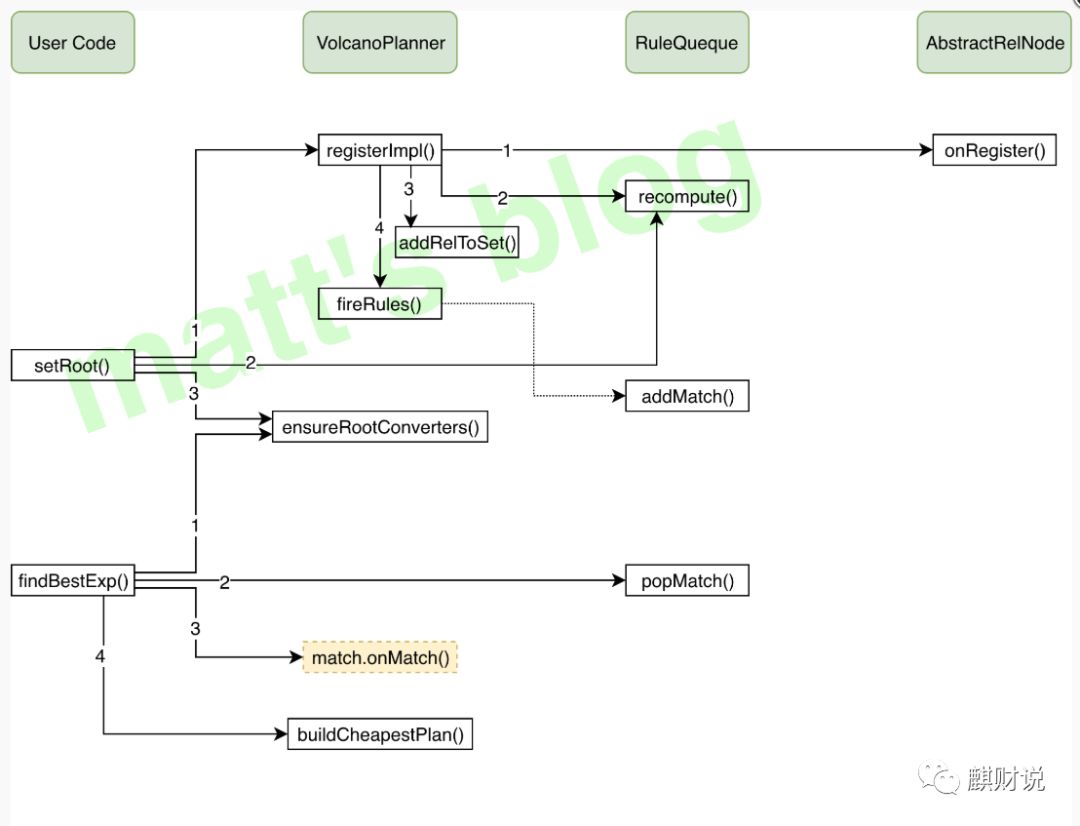
VolcanoPlanner 整体处理流程
1. 初始化 RuleQueue 时,添加的 one useless rule name 有什么用?
在初始化 RuleQueue 时,会给 VolcanoPlanner 的四个阶段都初始化一个 PhaseMatchList 对象(记录这个阶段对应的 RuleMatch),这时候会给其中的三个阶段添加一个 useless rule,如下所示:
1 2 3 4 5 6 7 8 9 10 | protected VolcanoPlannerPhaseRuleMappingInitializer
getPhaseRuleMappingInitializer() {
return phaseRuleMap -> {
// Disable all phases except OPTIMIZE by adding one useless rule name.
//note: 通过添加一个无用的 rule name 来 disable 优化器的其他三个阶段
phaseRuleMap.get(VolcanoPlannerPhase.PRE_PROCESS_MDR).add("xxx");
phaseRuleMap.get(VolcanoPlannerPhase.PRE_PROCESS).add("xxx");
phaseRuleMap.get(VolcanoPlannerPhase.CLEANUP).add("xxx");
};
}
|
开始时还困惑这个什么用?后来看到下面的代码基本就明白了
1 2 3 4 5 6 7 8 | for (VolcanoPlannerPhase phase : VolcanoPlannerPhase.values()) {
// empty phases get converted to "all rules"
//note: 如果阶段对应的 rule set 为空,那么就给这个阶段对应的 rule set 添加一个 【ALL_RULES】
//也就是只有 OPTIMIZE 这个阶段对应的会添加 ALL_RULES
if (phaseRuleMapping.get(phase).isEmpty()) {
phaseRuleMapping.put(phase, ALL_RULES);
}
}
|
后面在调用 RuleQueue 的方法会做相应的判断,如果 phaseRuleSet 不为 ALL_RULES,并且 phaseRuleSet 不包含这个 ruleClassName 时,那么就跳过这个 RuleMatch,也就是说实际上只有?OPTIMIZE?这个阶段是发挥作用的,其他阶段没有添加任何 RuleMatch。
2. 四个 phase 实际上只用了 1个阶段,为什么要设置4个阶段?
VolcanoPlanner 的四个阶段?,实际只有进行真正的优化操作,其他阶段并没有,这里自己是有一些困惑的:
为什么要分为4个阶段,在添加 RuleMatch 时,是向四个阶段同时添加,这个设计有什么好处?为什么要优化四次?
设计了4个阶段,为什么默认只用了1个?
这两个问题,暂时也没有头绪,有想法的,欢迎交流。




